Análisis descriptivo de variables de clasificación: fábricas de pienso y granjas
En el artículo anterior vimos cómo cargar en el ordenador el programa R y, con una sencilla programación (lo que hicimos fue escribir un script o guión), generar un gráfico muy ilustrativo. En el artículo de este mes activaremos una interfaz que nos ayudará a realizar los análisis de una forma más sencilla: cargaremos un fichero de datos desde una hoja de cálculo y analizaremos los datos allí incluidos. El archivo de datos tendrá dos variables categóricas o de clasificación y una variable cuantitativa.
Pero como ya dijimos, no vamos a aprender a programar, sino que realizaremos casi todos los ejemplos y análisis usando una interfaz de R denominada “R Commander”, que nos facilitará la tarea de analizar datos y hacer gráficos de una forma muy cómoda. En alguna ocasión, para mejorar un análisis o gráfico, sí usaremos algunas líneas de programación. Para seguir realizando lo que proponemos en este artículo hace falta tener conexión a Internet, ya que necesitaremos descargar varios ficheros.
COMENZAMOS
COMENZAMOS
Lo primero que haremos en esta sesión será ejecutar R (desde Inicio/programas/R). Una vez abierto R iremos a “Paquetes/Instalar paquetes(s)...” y nos aparecerá una ventana “CRAN mirror” que nos pregunta desde qué lugar queremos realizar la instalación del paquete que vamos a cargar. Podemos elegir “Spain(Madrid)” y aceptar con “OK”. Se abre otra ventana denominada “Packages” y elegiremos uno denominado “Rcmdr”, que es el que necesitaremos en la sesión de hoy. “Rcmdr”
se descargará del “mirror” elegido y se instalará en nuestro ordenador.
Paquetes de R
Los paquetes son colecciones de funciones, datos y código compilado en un formato definido de R.
Se guardan en nuestro ordenador en un directorio denominado “library”. La función “.libPaths()”
devuelve la ruta de donde está guardado ese directorio en nuestro ordenador y la función “library()”
nos dice qué paquetes tenemos en nuestro directorio “library”. Podemos escribir estas funciones en
nuestro programa R y ver qué pasa. A lo largo de esta serie descargaremos diferentes paquetes que nos permitirán realizar muchos cálculos estadísticos, así como gráficos muy potentes. Es en esta gran cantidad de paquetes donde reside la potencia de R. Sólo se instalan una vez y quedan guardados en el directorio “library”; estos paquetes pueden pasar de una versión a otra de R (actualizaremos el programa, pero no tendremos que descargarnos de nuevo los paquetes).
R COMMANDER
Una vez desargado el paquete “Rcmdr”, iremos a “Paquetes/Cargar paquete” y lo elegiremos (figura 1). La primera vez que cargamos este paquete nos solicitará instalar los paquetes accesorios que necesita (también necesitaremos acceso a Internet para hacerlo). Una vez cargados todos los paquetes accesorios, aparecerá otra ventana con una apariencia similar a muchos otros programas de Windows. Es muy útil acceder en “Rcmdr”, que a partir de ahora denominaremos R Commander, a la pestaña “Ayuda” y leer y descargar las ayudas que incorpora el sistema, (especialmente recomendamos leer “Ayuda/Introducción a R Commander”).Lo que vamos a hacer a continuación es cargar unos datos de un fichero Excel, que suele ser donde guardamos datos, e intentar realizar un sencillo análisis estadístico con “R Commander”. Vamos a trabajar con un fichero que se puede descargar en http://testsndtrials.blogspot.com.es. Crearemos un directorio para almacenar los ejercicios propuestos
a lo largo de esta serie y guardaremos el fichero en dicho directorio.
a lo largo de esta serie y guardaremos el fichero en dicho directorio.
Importar datos
Desde R Commander iremos a “Datos/Importar datos/ desde conjunto de datos Excel, Access o dBase...”, aceptaremos la siguiente ventana donde nos pregunta por el nombre que queremos darle
a nuestros datos con el nombre por defecto “Datos” y nos aparece una ventana desde donde tendremos que ir al directorio donde hemos grabado el archivo “numero2.xls” y seleccionar el archivo para cargarlo, indicándole en la siguiente ventana que sólo queremos usar la hoja 1. En la ventana de mensajes veremos que el conjunto debe tener 80 filas y 3 columnas.
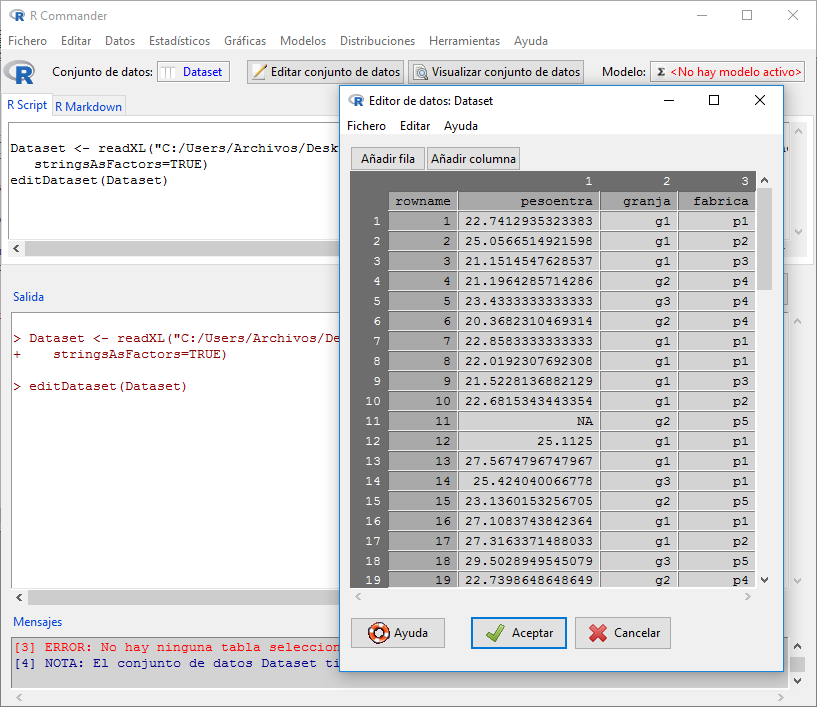
Ahora, si clicamos sobre el botón “Editar conjunto de datos” podremos ver y modificar nuestros datos en la ventana del programa R (no en la de R Commander), si fuera necesario (hay que cerrar la ventana al acabar, figura 2). El botón “Visualizar conjunto de datos” permite explorar los datos, sin posibilidad de editarlos.
Desde R Commander iremos a “Datos/Importar datos/ desde conjunto de datos Excel, Access o dBase...”, aceptaremos la siguiente ventana donde nos pregunta por el nombre que queremos darle
a nuestros datos con el nombre por defecto “Datos” y nos aparece una ventana desde donde tendremos que ir al directorio donde hemos grabado el archivo “numero2.xls” y seleccionar el archivo para cargarlo, indicándole en la siguiente ventana que sólo queremos usar la hoja 1. En la ventana de mensajes veremos que el conjunto debe tener 80 filas y 3 columnas.
Ahora, si clicamos sobre el botón “Editar conjunto de datos” podremos ver y modificar nuestros datos en la ventana del programa R (no en la de R Commander), si fuera necesario (hay que cerrar la ventana al acabar, figura 2). El botón “Visualizar conjunto de datos” permite explorar los datos, sin posibilidad de editarlos.
Empezamos a analizar
Los datos corresponden a un registro histórico de una empresa integradora de cerdos. Hay tres variables: el peso medio de entrada de los cerdos (variable cuantitativa), el nombre de la granja donde entramos esos cerdos y el nombre de la fábrica que suministró el pienso (variables cualitativas). Cada línea corresponde a un único registro (un peso, una granja y una fábrica).
Usaremos este archivo en futuros artículos para nuestros análisis.
A partir de aquí podremos responder a una serie de preguntas que nos interesan y que, al fin y al
cabo, sólo podremos contestar mediante los análisis estadísticos.
Usaremos este archivo en futuros artículos para nuestros análisis.
A partir de aquí podremos responder a una serie de preguntas que nos interesan y que, al fin y al
cabo, sólo podremos contestar mediante los análisis estadísticos.
¿Cuántas entradas hemos realizado en cada granja durante este tiempo? ¿A cuántas granjas ha facilitado pienso cada una de las fábricas?
Si queremos ver las entradas que ha tenido cada granja y cada fábrica, seleccionamos “Estadísticos/Resúmenes/Distribuciones de frecuencias” y elegimos granja y fábrica (como en otras aplicaciones, para elegir dos variables se debe mantener presionada la tecla Ctrl a la vez que seleccionamos cada variable). Aceptamos y en la pantalla inferior veremos los resultados.
Queríamos que cada granja tuviera un número parecido de entradas, así como que cada fábrica dispensase pienso a un número similar de entradas.
¿Hemos cumplido nuestro objetivo?
Para responder a esta pregunta debemos realizar un test de hipótesis de Chi-cuadrado. En este caso comprobaremos si la distribución de frecuencias (esto es la proporción de animales en cada granja, o la proporción de entradas que dispensa cada fábrica) sigue una distribución teórica.
La hipótesis nula o H0 (la afirmación que se intenta rebatir con el estudio estadístico) es que la variable sigue la distribución teórica que proponemos. Volviendo a realizar el ejercicio anterior, si seleccionamos la casilla que activa el test Chi-cuadrado, y aceptamos la distribución hipotética que el sistema nos muestra por defecto (igual proporción en todos los niveles), que es la teórica que nosotros pensábamos, llenar el mismo número de veces cada granja y que cada fábrica suministrase pienso al mismo número de entradas, obtendremos el resultado de comprobar si la distribución de granjas o fábricas sigue la distribución teórica o no.
A la H0 de “se han realizado el mismo número de entradas en cada granja” obtenemos un valor de p=1,492e-05, en este caso, con un nivel de significación de 0,05 (aceptamos equivocarnos un 5% de las veces al rechazar la H0) y teniendo en cuenta que el valor p es menor que el nivel de significación, concluimos que podemos rechazarla y que tenemos razones para pensar que no hay igual proporción de entradas en cada granja. Para la de las fábricas obtenemos una p=0,0007019, luego las fábricas no han suministrado pienso al mismo número de engordes.
¿A cuántas entradas de cerdos por granja ha suministrado pienso cada fábrica?
La solución a esta pregunta la obtendremos realizando una tabla de doble entrada. Seleccionamos “Estadísticos/Tablas de contingencia/Tabla de doble entrada...” y elegimos una variable para fila y otra columna y obtendremos el número de entradas por fábrica y granja de este histórico. Si seleccionamos las diferentes opciones que nos ofrece esta ventana, obtendremos los resultados de una forma u otra.
En este caso, si solicitamos el test Chi-cuadrado estamos estudiando la asociación entre las dos variables, granjas y fábricas, y la pregunta que podemos contestar es ¿las diferentes fábricas sirven de forma proporcional a las diferentes granjas, o existe una asociación entre algunas fábricas y algunas granjas? Para nuestro ejemplo, la hipótesis nula es que la proporción de entradas es homogénea entre granjas y fábricas (las dos variables son independientes). El valor de p siempre es 7,8e-11, por lo que
concluiremos (p es menor que 0,05) que hay fábricas que suministran más a unas granjas que a otras, o que ambas variables no son independientes.
concluiremos (p es menor que 0,05) que hay fábricas que suministran más a unas granjas que a otras, o que ambas variables no son independientes.
¿PODEMOS VER ESTOS RESULTADOS EN UNOS GRÁFICOS?
Para realizar gráficos con estos datos, seleccionamos “Gráficas/Gráfica de barras...” y la variable que queremos representar, obteniendo gráficos de las mismas (figura 3). Estos se pueden guardar en diferentes formatos para ser usados en presentaciones u otros documentos. El lector puede tratar de realizar diferentes tipos de gráficos con estos datos, si utiliza las distintas opciones que el menú gráficos nos ofrece.
¿CÓMO GUARDO LOS DATOS, LAS INSTRUCCIONES, LOS RESULTADOS Y LOS GRÁFICOS?
Todo lo realizado hasta ahora ha quedado guardado en las ventanas de instrucciones y de resultados. Podemos guardar el conjunto de datos importado en “Datos/Conjunto de datos activo/Guardar el conjunto de datos activo”. También podemos guardar el código generado para usar en otra ocasión y también los resultados.
Si vamos a “Fichero/Guardar las instrucciones como...” guardaremos las instrucciones y con “Fichero/Guardar los resultados como...” guardaremos los resultados. Los gráficos podemos guardarlos una vez que se generan, si seleccionamos “Gráficas/Guardar gráfico en fichero...” y elegimos la opción que más nos interese.Para salir de la sesión de R debemos ir a “Fichero/Salir/De Commander y R”.


Comentarios
Publicar un comentario