Contando sujetos y analizando los resultados
Tras un curso de iniciación a la estadística en producción animal, una compañera nos envió la siguiente pregunta: “La chi cuadrado (χ) se utilizaba para determinar la asociación o independencia de dos variables cualitativas, pero ¿qué me aporta saber que X-Squared = 19.25?”.
Evidentemente nuestra primera reflexión fue que no habíamos sabido transmitir el significado que subyace en el test específico de χ2, pero más preocupante es que no habíamos sabido transmitir que los test estadísticos son herramientas para analizar los datos, es decir, para darnos información de nuestros datos.
En los próximos capítulos vamos a ver cómo obtener información a partir de datos obtenidos por
conteos, utilizando las herramientas adecuadas,es decir, los test estadísticos (χ en este caso).
Habitualmente, en nuestra práctica diaria obtenemos muchos datos procedentes de con tajes, por ejemplo, individuos. Calculamos el porcentaje de mortalidad de una granja contando los cerdos muertos, el porcentaje de abortos contando el número de cerdas que abortan, y así en un sinfín de variables. Obtenemos datos de variables explicativas categóricas (por ejemplo: muertos/vivos) y los comparamos bien con unos valores estándar obvien con unos valores esperados.
Antes de pasar a aplicar el test estadístico correspondiente mediante R, veamos la lógica del análisis de unos datos procedentes de conteos.
EL PROBLEMA
Un producto dice tener la propiedad de disminuir el número de cerdas que tienen una repetición tras la inseminación artificial… ¿Nos fiamos? Mejor lo comprobamos. Para este ejemplo, dan igual las circunstancias biológicas o productivas que se producen en torno al experimento. Lo que queremos mostrar es la lógica que subyace en el análisis.

Imaginemos los datos de la tabla 1, donde se muestra el resumen del resultado de aplicar el producto A en una serie de cerdas sobre las repeticiones a celo. Nuestra suposición es que el uso del producto Ano influye en el hecho de que las cerdas muestren repeticiones de celo. Entonces habrá una hipótesis nula (H; ver “Análisis descriptivo de variables de clasificación: fábricas de pienso y granjas” Suis nº 87), mientras que la hipótesis alternativa (H) será que el producto A sí influye en la repetición de celo (disminuye el número de cerdas que repiten):
■ H: el uso del producto A es independiente deque se produzcan repeticiones de celo.
■ H: el uso del producto A no es independientemde que se produzcan repeticiones de celo.
Recordamos a los lectores que el hecho de rechazar la hipótesis nula no implica el hecho de aceptar la alternativa.
COMENZAMOS A RESOLVER EL PROBLEMA: CONSTRUCCIÓN DE LA TABLA DE CONTINGENCIA
 En primer lugar vamos a ver cómo hemos construido la tabla 1 (tabla de contingencia) a través de un archivo Excel y la opción de “Tabla dinámica”.Abrimos un archivo Excel vacío y en la primera fila ponemos los nombres de las variables: “Crotal”(columna A), “Producto A” (columna B) y “Resultado” (columna C) (figura 1).
En primer lugar vamos a ver cómo hemos construido la tabla 1 (tabla de contingencia) a través de un archivo Excel y la opción de “Tabla dinámica”.Abrimos un archivo Excel vacío y en la primera fila ponemos los nombres de las variables: “Crotal”(columna A), “Producto A” (columna B) y “Resultado” (columna C) (figura 1).
Ya hemos realizado el experimento y ya hemos llenado nuestra tabla de datos, con lo que entonces tenemos la figura 2.

¿Cómo construimos ahora desde estos
datos la tabla 1?
Sigamos los siguientes pasos:
■ Seleccionamos todos los datos: situamos el cursor en la celda A1 y manteniendo las teclas “Ctrl” y“mayúsculas izquierda” presionadas, presionamos la tecla de “flecha derecha” ⇒ y “flecha abajo” ⇓ y así seleccionamos todos los datos.
■ Una vez seleccionados, vamos a “Insertar” y seleccionamos el icono “Tabla dinámica” (figura 3).

■ Aceptamos y aparecerá otra ventana. Arrastraremos el campo “Producto A” a “Rótulos de columna” y en la casilla “Rótulos de fila” el campo“Resultado”. En la casilla “Valores” pondremos el campo “Crotal”. Sobre este campo, con el botón izquierdo desplegaremos un menú donde la opción “Configuración de campo de valor” y elegiremos “Cuenta”. En la figura 4 aparecen todos estos pasos.

SEGUNDO PASO. TABLA DE DATOS ESPERADOS
Para sacar información de la tabla 1 (¿funciona el
producto A para disminuir la repetición de celo en cerdas?) tenemos que compararlo con “algo”.
¿Cómo sería la tabla de contingencia si la hipótesis nula fuera cierta? Una lógica que podemos
usar para construir esta tabla es que las frecuencias marginales nos permiten calcular los datos esperados de cada exposición. Lo veremos con un ejemplo: la frecuencia esperada de la celda dondetenemos las cerdas que han recibido el producto A(columna “Sí”) y no han repetido celo (fila “No repiten”) se calcula siguiendo la siguiente ecuación:








Evidentemente nuestra primera reflexión fue que no habíamos sabido transmitir el significado que subyace en el test específico de χ2, pero más preocupante es que no habíamos sabido transmitir que los test estadísticos son herramientas para analizar los datos, es decir, para darnos información de nuestros datos.
En los próximos capítulos vamos a ver cómo obtener información a partir de datos obtenidos por
conteos, utilizando las herramientas adecuadas,es decir, los test estadísticos (χ en este caso).
Habitualmente, en nuestra práctica diaria obtenemos muchos datos procedentes de con tajes, por ejemplo, individuos. Calculamos el porcentaje de mortalidad de una granja contando los cerdos muertos, el porcentaje de abortos contando el número de cerdas que abortan, y así en un sinfín de variables. Obtenemos datos de variables explicativas categóricas (por ejemplo: muertos/vivos) y los comparamos bien con unos valores estándar obvien con unos valores esperados.
Antes de pasar a aplicar el test estadístico correspondiente mediante R, veamos la lógica del análisis de unos datos procedentes de conteos.
EL PROBLEMA
Un producto dice tener la propiedad de disminuir el número de cerdas que tienen una repetición tras la inseminación artificial… ¿Nos fiamos? Mejor lo comprobamos. Para este ejemplo, dan igual las circunstancias biológicas o productivas que se producen en torno al experimento. Lo que queremos mostrar es la lógica que subyace en el análisis.
Imaginemos los datos de la tabla 1, donde se muestra el resumen del resultado de aplicar el producto A en una serie de cerdas sobre las repeticiones a celo. Nuestra suposición es que el uso del producto Ano influye en el hecho de que las cerdas muestren repeticiones de celo. Entonces habrá una hipótesis nula (H; ver “Análisis descriptivo de variables de clasificación: fábricas de pienso y granjas” Suis nº 87), mientras que la hipótesis alternativa (H) será que el producto A sí influye en la repetición de celo (disminuye el número de cerdas que repiten):
■ H: el uso del producto A es independiente deque se produzcan repeticiones de celo.
■ H: el uso del producto A no es independientemde que se produzcan repeticiones de celo.
Recordamos a los lectores que el hecho de rechazar la hipótesis nula no implica el hecho de aceptar la alternativa.
COMENZAMOS A RESOLVER EL PROBLEMA: CONSTRUCCIÓN DE LA TABLA DE CONTINGENCIA

Ya hemos realizado el experimento y ya hemos llenado nuestra tabla de datos, con lo que entonces tenemos la figura 2.

¿Cómo construimos ahora desde estos
datos la tabla 1?
Sigamos los siguientes pasos:
■ Seleccionamos todos los datos: situamos el cursor en la celda A1 y manteniendo las teclas “Ctrl” y“mayúsculas izquierda” presionadas, presionamos la tecla de “flecha derecha” ⇒ y “flecha abajo” ⇓ y así seleccionamos todos los datos.
■ Una vez seleccionados, vamos a “Insertar” y seleccionamos el icono “Tabla dinámica” (figura 3).

■ Aceptamos y aparecerá otra ventana. Arrastraremos el campo “Producto A” a “Rótulos de columna” y en la casilla “Rótulos de fila” el campo“Resultado”. En la casilla “Valores” pondremos el campo “Crotal”. Sobre este campo, con el botón izquierdo desplegaremos un menú donde la opción “Configuración de campo de valor” y elegiremos “Cuenta”. En la figura 4 aparecen todos estos pasos.

SEGUNDO PASO. TABLA DE DATOS ESPERADOS
Para sacar información de la tabla 1 (¿funciona el
producto A para disminuir la repetición de celo en cerdas?) tenemos que compararlo con “algo”.
¿Cómo sería la tabla de contingencia si la hipótesis nula fuera cierta? Una lógica que podemos
usar para construir esta tabla es que las frecuencias marginales nos permiten calcular los datos esperados de cada exposición. Lo veremos con un ejemplo: la frecuencia esperada de la celda dondetenemos las cerdas que han recibido el producto A(columna “Sí”) y no han repetido celo (fila “No repiten”) se calcula siguiendo la siguiente ecuación:
Y entonces tendremos:

Si procedemos así con el resto de las celdas obtendremos la tabla 2 y la figura 5.


χ2, POR FIN
¿Son diferentes los datos esperados de los observados?
Esto es lo que nos resuelve la prueba χ esto es lo que necesitamos saber. Este estadístico(χ2) se calcula con la siguiente ecuación:

Donde:
■ E = número esperado de datos en la celda correspondiente.
■ O = número observado de datos en la celda correspondiente.
Y por lo tanto, nuestro resultado es: χ2 = 0,5219.
¿Funciona entonces el producto A?
Debemos comparar este valor con el estadístico χ
correspondiente. En este caso, asumimos un errorα = 0,05 y nuestros datos tienen 1 grado de libertad. El número de grados de libertad (df por sus siglas en inglés) es igual a:

En nuestro caso df = 1. Volveremos sobre este concepto en los siguientes números.
Si en nuestro archivo Excel escribimos “=DISTR.CHI(0,5219;1)”, el resultado es la probabilidad de la distribución χ2, que en nuestro caso es igual a 0,470, es decir, p=0,470. Este resultado (al ser mayor que el error asumido) no nos permite rechazar la hipótesis nula, así que la aceptamos como válida. En nuestro caso, aceptamos que la aplicación del producto A era independiente dela repetición de celo de las cerdas, es decir, el producto A no funciona.
Un atajo en Excel
Excel también nos proporciona directamente la probabilidad asociada a nuestra tabla 1. Si volvemos a Excel y en una celda escribimos “=PRUEBA.CHI(B5:C6;B15:C16)” (suponiendo que nuestros datos estén como en la figura 5) obtendremos directamente el valor p=0,47.
MUY FÁCIL CON R
¿Cómo lo haríamos con R? Abrimos R, cargamos RCommander con library(Rcmdr), cargamos los datos desde Datos/Importar datos/Desde un archivo Excel… (el fichero se denomina chi cuadrado.xls , archivo para descargar al final del post) y elegimos la hoja donde tengamos los datos tal como se muestran en la figura 2.
Entonces vamos a Estadísticos/Tablas de contingencia/Tablas de doble entrada… y en la variable fila elegimos “Resultado” y en la variable columna elegimos “Producto A” (figura 6). También podemos elegir “Resultado” como variable columna y“Producto A” como variable fila.
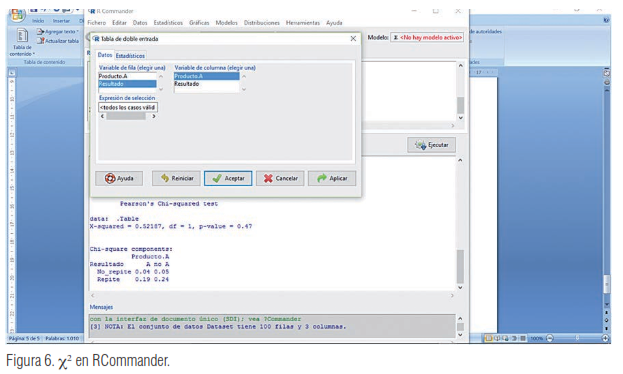
En la pestaña Estadísticos, elegimos no calcular porcentajes y calcular el test de independencia de χ
. Obtendremos la figura 7 (que nos da el mismo resultado que el calculado en Excel.
Veremos más aplicaciones y complicaciones del test de independencia de χ2 en los próximos números, así como más aplicaciones sobre los conteos.

Archivos para descargar:

Comentarios
Publicar un comentario